«Akka representa muchos conceptos nuevos que al principio cuesta asimilar. Para poder entenderlo mejor, he ido creando, poco a poco, una serie de ejemplos que me han permitido comprender mejor el paradigma que conlleva.
![[Akkapor ejemplos]](/wp-content/uploads/2015/10/akkaExample.png)
Este artículo trata sobre esto, intentar tener una prueba de código de cada nuevo concepto que permita ver cual es su comportamiento y función.»
Entrada siguiente: Akka por ejemplos. Sobre supervisión, bus de eventos, …
Akka es un framework basado en el modelo de actores que permite dar solución al problema de la programación concurrente. Además de formar parte de Scala de manera nativa existe como librería en Java.
Permite diseñar aplicaciones que sean escalables horizontalmente de manera transparente, con alta toleracia a fallos y basada en eventos que permite cumplir el ‘manifiesto reactivo‘.
Este será el primer de una seríe de artículos explicando conceptos clave que se utilizan en Akka mediante ejemplos. En esta primera parte trataré como funciona las colas de mensajes de un actor, que es un router y las diferentes maneras de como se pueden enviar mensajes entre actores.
En próximas entregas trataré sobre el sistema de supervisión de los actores en Akka, como funciona el bus de eventos y que son los actores tipados.
Esta entrada es eminentemente práctica, te invito a descargarte el proyecto y a que eches un vistazo y ejecutes los ejemplos. Se entenderá mejor lo que quiero explicar en este artículo. Todo el código fuente relacionado con esta serie de post está disponible en mi repositorio de GitHub
![[Logo GitHub]](/wp-content/uploads/2013/09/GitHub-Mark-32px.png) AkkaActorsAndFutures
AkkaActorsAndFutures
Sobre los test
La idea fundamental a la hora de realizar los test ha sido la de realizar implementaciones dummy y ‘ad hoc‘ y, gracias a ellas, montar test que permitieran ver con facilidad cual es el funcionamiento de la pieza que interesa.
Por otra parte, he buscado que el código incluido en los test puedan servir de ejemplo uando se quiera implementar ese mismo concepto en una aplicación real.
Es por esto por lo que he evitado utilizar el framework de Akka de test ‘akka-testkit’ y en algunos momentos puede parecer que me he complicado la vida realizando las validaciones cuando se completan los futuros y utilizando agentes de Akka para compartir estados entre actores.
Mucha de la funcionalidad común a todos los actores, como crear el sistema de actores y métodos de utilidad se ha llevado a test base (TestBase y TestBaseTypedActor ) de los que heredan todos los test.
Prólogo: Los agentes
Ya que en los test utilizo agentes, antes de entrar a explicar los test, intentaré hacer una breve introdución de lo que es un agente en Akka.
Un agente de Akka permite almacenar un valor y actualizarlo sin problemas de concurrencia. Tienen la particularidad que la actualización se realiza de manera asíncrona, pero se puede leer el valor de manera síncrona.
Su funcionamiento es similar a un mailbox de un actor. Se basa en encolar los nuevos valores de tal manera que el valor interno se va actualizando en orden de llegada. No existe concurrencia y por eso su actualización es asíncrona.
Hay que tener en cuenta que cuando se pide su valor de manera síncrona devuelve el valor ‘actual‘ no el valor ‘futuro‘ que tendrá cuando se procesen todos los valores encolados hasta ese momento.
Vamos entonces con los test.
Como funciona la cola de mensajes de un Actor
Test: ActorQueueTest.java
Commando maven:
mvn −Dtest=com.logicaalternativa.examples.akka.queue.ActorQueueTest test
![[Un actor, un mailbox]](/wp-content/uploads/2015/10/maibox-e1444336153949.png)
Un actor, un mailbox
El modelo de actores nos asegura que
no puede haber más de una ejecución concurrente de un actor. Es decir, no puede haber más de un hilo ejecutando el código de actor. Los mensajes que se envían al actor se encolan en su ‘
inbox‘ de tal manera que se ejecutan de uno en uno.
En este ejemplo se está levantando dentro del sistema de actores, un actor del tipo ActorNoTypedDummy. Este tiene una lógica muy sencilla: si se envía un mensaje tipo Long la ejecución se espera los milisegundos indicados en el valor del mensaje. Si el mensaje es de tipo String devuelve un eco del mensaje.
En el test ActorQueueTest se envía un primer mensaje tipo Long para que se realice una espera y después 10 mensajes de tipo String.
En en la ejecución del test, se puede observar de que aunque se envían todos los mensajes sin esperar la ejecución del actor, en realidad estos se encolan. El actor no procesa el siguiente mensaje hasta que no ha terminado la ejecución anterior.
El resultado es que los mensajes son procesados por orden de llegada ya que este actor tiene la implementación por defecto de ‘mailbox‘ (existen otras implementaciones que permiten prioridades de mensajes). Con lo que realiza la espera del primero de ellos y después el eco del resto.
En este test para comprobar el orden de los mensajes que se están ejecutando en el actor se está utilizando un agente de Akka para guardar el estado de manera asíncrona. El agente almacena la concatenación de los mensajes tipo cadena que se envían al actor.
Para verificar que el orden de los mensajes enviados es el mismo orden de los mensajes que se han procesado se comprueba que estas dos cadenas son iguales.
Cómo funciona un Router
Test: ActorQueueRouteRoundRobinTest.java
Commando maven
mvn −Dtest=com.logicaalternativa.examples.akka.queue.ActorQueueRouteRoundRobinTest test
Akka permite el concepto de ‘
Router‘. Esto permite asociar en una misma referencia de un actor envolver un grupo de actores del mismo tipo.
Se basa en el mismo concepto que tenemos todos en mente de que es un Router: un frontal al que se envían los mensajes y que se encarga de reenviarlos a sus ‘routees‘ para que estos los procesen y devolver la respuesta.
Permite un procesamiento en paralelo mayor, al existir más instancias de un actor, pero con la comodidad de tener una referencia única a la que enviar los mensajes.
![[Concepto de router]](/wp-content/uploads/2015/10/router-peque.png)
Router
Cada miembro del router es de hecho un actor y tiene su propia cola. La estrategia del envío de los mensajes a los miembros del enrutador se define al crear este. En el test de ejemplo se está utilizando la estrategia de envío secuencial de mensajes (
‘RoundRobinPool’): se envía un mensaje a un actor del grupo, el siguiente al siguiente actor y así sucesivamente. En la documentación de
Akka puedes ver que existen y se pueden utilizar otras estrategias.
El ejemplo levanta un sistema de actores. Se crea un router de 5 actores del tipo ActorNoTypedWhoIam. Este actor tiene una implementación muy sencilla. Se limita a responder en un Map con el mismo mensaje que le envían y su nombre de actor.
Al router se le envían 10 mensajes. En la resolución de cada futuro de respuesta se comprueba que el mensaje es el mismo que se ha enviado. Por otra parte, gracias a la nombre del routee, se guarda la información de que routee ha procesado el mensaje.
Por último se comprueba que a cada actor del grupo del router le ha llegado el mismo número de mensajes (estrategía de envío RoundRobinPool). En este caso son 2 ya que el router lo forman 5 actores y se mandan 10 mensajes.
En las trazas se puede comprobar que el actor con el nombre ‘a‘ le llegan los mensajes ‘0‘ y ‘5‘, al ‘b‘ el ‘1‘ y el ‘6‘ y así sucesivamente.
Como se pueden enviar mensajes entre actores
Test: ActorProxyTest.java
Comando maven
mvn -Dtest=com.logicaalternativa.examples.akka.message.ActorProxyTest test
Fundamentalmente los actores se pueden enviar mensajes de dos maneras diferentes: tipo ‘
fire & forget‘ (dispara y olvida) utilizando la función ‘
tell‘ o bien seguir un esquema
petición-respuesta utilizando la función ‘
ask‘.
Por otra parte un actor puede crear otros actores a los que necesita enviar mensajes. Es muy común que existan actores cuya tarea sea la de orquestar o supervisar el trabajo de los actores que ha creado (‘actores hijos’), y que una parte de esta tarea sea la de reenviar a sus hijos los mensajes que les llegan. Para estos cosos es muy útil utilizar la función ‘forward‘
El ejemplo se crea un actor ActorNoTypedProxy que crea un actor hijo del tipo ActorNoTypedDummy. Recordemos que este último devuelve un echo de los mensajes que se le envían.
ActorNoTypedProxy hará de proxy para mostrar las diferentes formas de enviar y reenviar mensajes entre actores. Recibe los siguientes mensajes tipo cadena:
‘forward‘, redirigir el mensaje
Commando maven test 'forward'
mvn -Dtest=com.logicaalternativa.examples.akka.message.ActorProxyTest#testForward test
Cuando recibe un mensaje de este tipo ejecuta llamada al método ‘
forward‘ del actor hijo, con el mismo mensaje. El actor hijo (
ActorNoTypedDummy) recibirá el mensaje como si el emisor hubiera sido el que emitió el mensaje al actor
ActorNoTypedProxy.
‘redirect‘ dispara y olvida
Comando maven test redirect
mvn -Dtest=com.logicaalternativa.examples.akka.message.ActorProxyTest#testRedirectMessageToChild test
El actor que hace de proxy redirecciona el mensaje llamando a la función ‘
tell‘ del hijo indicando que el remitente es el del mensaje original que le llega al proxy. Aquí también el actor hijo (
ActorNoTypedDummy) recibirá el mensaje como si el emisor hubiera sido el que emitió el mensaje a
ActorNoTypedProxy.
![[forward o 'redirect']](/wp-content/uploads/2015/10/forward-peque.png)
forward o ‘redirect’
‘future‘, petición-respuesta no bloqueante y asíncrona
Comando maven test 'future'
mvn -Dtest=com.logicaalternativa.examples.akka.message.ActorProxyTest#testFutur test
Este es un ejemplo de comportamiento
no bloqueante y
asíncrono utilizando los
futuros de
Scala que ofrece
Akka.
ActorNoTypedProxy utiliza la función ‘
ask‘ para con el mismo mensaje que le ha llegado, preguntar al actor hijo
ActorNoTypedDummy y obtener el futuro de la respuesta. Este futuro se envía al remitente del mensaje original.
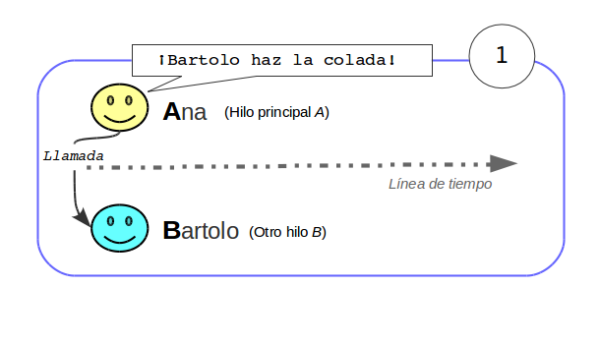
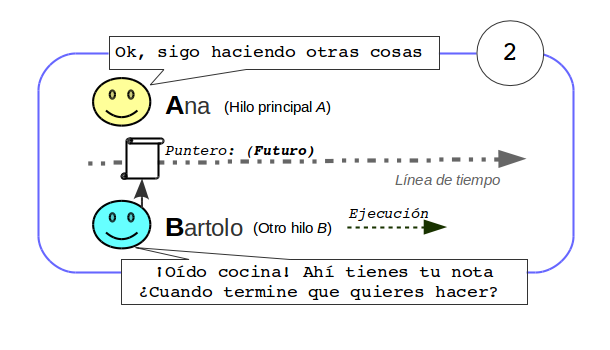
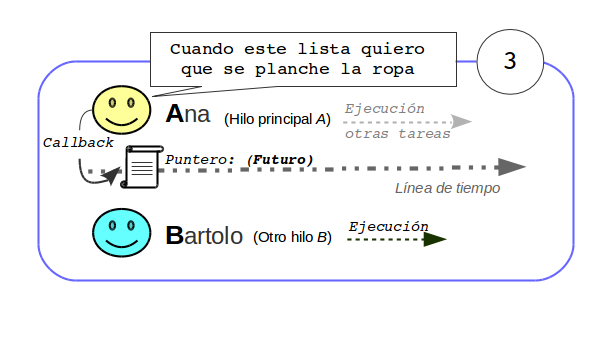
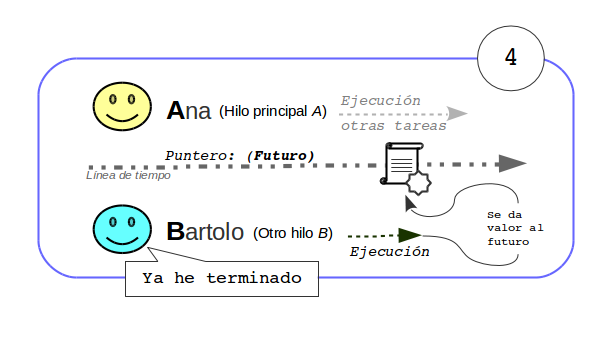
Al ser este un futuro, si fuera necesario, se puede desde el actor que hace de proxy, operar con él o realizar cualquier tipo de transformación. Por ejemplo se puede registrar un callback, realizar alguna transformación operando con el de manera funcional, etc…
Para simplificar en el test se espera el resultado de la respuesta y como esta también es un futuro, se espera también a este para obtener el resultado.
‘await‘, petición-respuesta bloqueante y síncrona
Comando maven test 'await'
mvn -Dtest=com.logicaalternativa.examples.akka.message.ActorProxyTest#testAwaitFutur test
Sigue el mismo esquema que el test anterior pero esperado la respuesta de una manera
síncrona.
En el actor proxy realiza la misma llamada ‘ask‘ y a continuación se utiliza la función ‘Await‘ que espera la resolución del futuro. Se obtiene así un comportamiento bloqueante y síncrono de petición-respuesta.
Hasta aquí llega esta primera parte de esta serie de artículos centrados en explicar como funciona Akka con ejemplos. Conceptos como la supervisión entre actores, el bus de eventos y que son los actores tipados serán material de futuras entregas.
Espero que os sirva.
M.E.
Entrada siguiente: Akka por ejemplos. Sobre supervisión, bus de eventos, …

 Diapositivas presentación: Tipos algebraicos en Java 21
Diapositivas presentación: Tipos algebraicos en Java 21

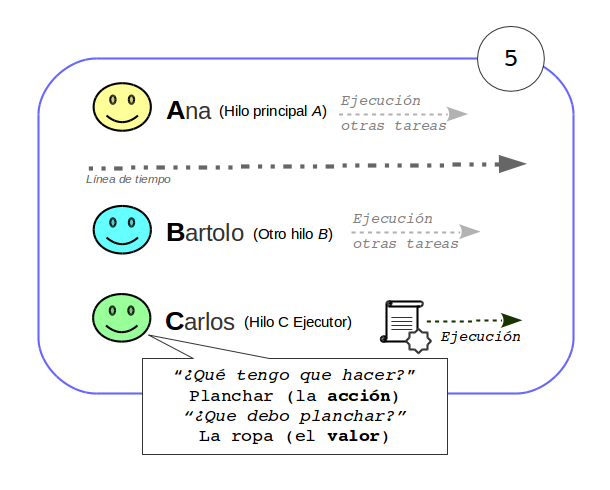
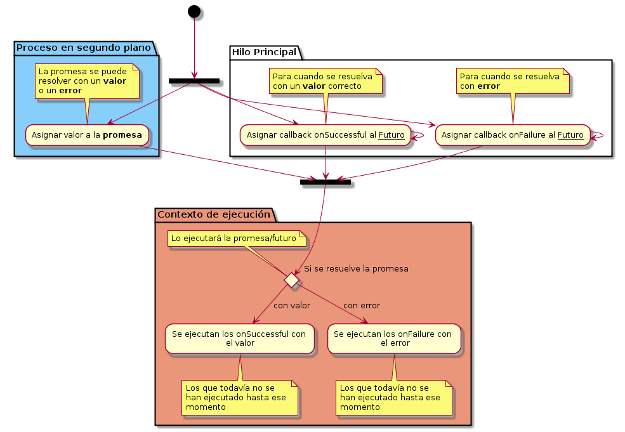
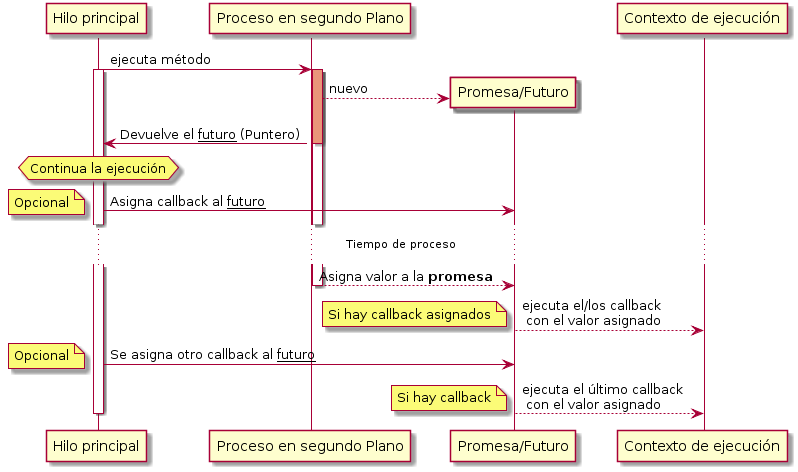
![[Actor tipado]](/wp-content/uploads/2015/10/typedActor-peque.png)
![[Supervisión padre-hijo en Akka]](/wp-content/uploads/2015/10/supervision-peque.png)
![[Bus de eventos de Akka]](/wp-content/uploads/2015/10/busEvent-peque2.png) El paradigma cambia. En vez de enviar un mensaje a un actor concreto, es decir, “(Por favor) haz esto”, cuando se publica un mensaje en el bus se está diciendo “(A quien pueda interesar) ha ocurrido esto”
El paradigma cambia. En vez de enviar un mensaje a un actor concreto, es decir, “(Por favor) haz esto”, cuando se publica un mensaje en el bus se está diciendo “(A quien pueda interesar) ha ocurrido esto”![[Mock y test]](/wp-content/uploads/2014/10/mockAndTest_p.png) Este es el segundo y último artículo de la serie que completa el anterior post
Este es el segundo y último artículo de la serie que completa el anterior post ![[Pantallazo de la Demo Ejemplo Mock]](/wp-content/uploads/2014/10/pantallazoEjemploMock.png)
![[Grunt logo]](/wp-content/uploads/2014/05/grunt.png) En un proyecto me tocó realizar una ‘builtool‘. Era una herramienta común que utilizarían todos los demás proyectos no importando su tecnología, PHP,.Net, Java, etc. Obtenía el código del sistema de control de versiones compilaba, paquetizaba y subía la build compilada a otra rama del control de versiones. En realidad era un pre-Maven porque obligaba a una cierta estructura de directorios en los proyectos pero no tenía ni su control de dependencias, ni sus arquetipos para nuevos proyectos. La herramienta estaba hecha en Ant.
En un proyecto me tocó realizar una ‘builtool‘. Era una herramienta común que utilizarían todos los demás proyectos no importando su tecnología, PHP,.Net, Java, etc. Obtenía el código del sistema de control de versiones compilaba, paquetizaba y subía la build compilada a otra rama del control de versiones. En realidad era un pre-Maven porque obligaba a una cierta estructura de directorios en los proyectos pero no tenía ni su control de dependencias, ni sus arquetipos para nuevos proyectos. La herramienta estaba hecha en Ant.
 La duración de manga de motocross se mide en minutos + 2 vueltas. A nivel regional son 20 minutos + 2 vueltas, a nivel nacional 30 minutos + 2 vueltas, etc… Entrenando lo normal es hacer mangas de la misma duración, o de menos tiempo (mejorando la rapidez) o de más (mejorando el fondo). Las motos de cross no tienen instrumentación y obliga a que una persona desde fuera indique al piloto cuanto le queda de manga.
La duración de manga de motocross se mide en minutos + 2 vueltas. A nivel regional son 20 minutos + 2 vueltas, a nivel nacional 30 minutos + 2 vueltas, etc… Entrenando lo normal es hacer mangas de la misma duración, o de menos tiempo (mejorando la rapidez) o de más (mejorando el fondo). Las motos de cross no tienen instrumentación y obliga a que una persona desde fuera indique al piloto cuanto le queda de manga. Completando la
Completando la