Esta es la segunda entrega de Akka por ejemplos. La primera trató sobre cual es el funcionamiento de la cola de mensajes de un actor, que es un router y como se envían mensajes entre actores.
Ahora se tratarán temas como el control de fallos y la supervisión de actores, el bus de eventos de Akka y sobre los ‘Dead Letters’
Entrada anterior: Akka por ejemplos
Sin más vamos con los ejemplos.
Todo el código fuente relacionado con esta serie de posts está disponible en mi repositorio de GitHub
Control de fallos: Supervisión y monitorización.
![[Supervisión padre-hijo en Akka]](/wp-content/uploads/2015/10/supervision-peque.png)
[Supervisión padre-hijo en Akka]
Se crea así una jerarquía en forma de árbol en la que la que los actores padres supervisan a los actores hijos. El actor ‘user‘ de Akka será el padre de primera generación de actores que hayamos creado.
Esto es realmente lo que te da la robustez (‘resilence‘) que un sistema reactivo necesita. Esta robustez se pierde cuando se intenta en vez de tener esta jerarquía, ir a un esquema con una mentalidad más tradicional de inyección de dependencias y se cae en la tentación de inyectar actores a otros actores.
Cuando un actor falla y se produce una excepción, su supervisor puede hacer, o bien reiniciar el actor, parar el actor, escalar la excepción o absorber la excepción y continuar con la ejecución.
El sistema de supervisión de Akka permite tener la posibilidad de diferente respuesta del supervisor dependiendo del tipo de excepción y si esta afecta a todos los actores supervisados o sólo al que ha fallado. Esto junto con lo anterior permite implementar fácilmente patrones, por ejemplo de tipo ‘circuit breaker‘, si uno de los actores falla.
Akka tiene la posibilidad de establecer eventos o disparadores en el ciclo de vida de un actor. Por ejemplo antes de crearlo, antes y después de reiniciarlo y cuando se para.
Ademas del concepto de supervisión, en Akka existe el de monitorización. Cualquier actor, puede ‘monitorizar‘ a cualquier otro, lo haya creado o no. El primero obtiene un mensaje ‘Terminated‘ cuando el monitorizado ha terminado. Esto permite modificar su comportamiento o cambiar su estado. En los ejemplos siguientes el actor supervisor también hace de ‘monitor‘ de sus hijos.
Para poder mostrar con ejemplos como es el comportamiento de las diferentes estrategias a seguir, he creado en el proyecto dos actores: ActorNoTypedDummyCheckLifeCycle y ActorNoTypedLetItCrash.
ActorNoTypedDummyCheckLifeCycle se utiliza para comprobar los eventos que se disparan y por los ‘estados‘ que pasa un actor cuando es supervisado con diferentes estrategias. Concatena en un atributo ‘state‘ los diferentes pasos por los ‘hooks‘ del ciclo de vida de un actor:
- Método ‘aroundPreStart‘: Primer evento que se dispara cuando se inicia un actor. Sólo se ejecuta cuando se inicia un actor por primera vez.
- Método ‘preStart’: Se lanzan cuando se inicia un actor o después de que se haya reiniciado.
- Método ‘aroundPreRestart’: Cuando un actor va a ser reiniciado, se dispara antes de parada el actor.
- Método ‘preRestart‘: También se ejecuta antes de parar el actor cuando va a ser reiniciado. La llamada es después de la del método ‘aroundPreRestart‘
- Método ‘postStop‘: Evento que se llama, o bien cuando se para el actor, o bien antes de reiniciarlo (en este último caso justo después de que se llame al método ‘preRestart‘)
- Método ‘postRestart‘: Se lanza después de reiniciar el actor.
- Método ‘aroundPostStop‘: Se realiza la llamada justo antes de parar definitivamente el actor.
El actor ActorNoTypedLetItCrash es el que creará y hará de supervisor de ActorNoTypedDummyCheckLifeCycle. En su constructor, permite definir por parámetro la estrategia de supervisión. Su comportamiento será en de hacer de proxy en el envío de mensajes a ActorNoTypedDummyCheckLifeCycle hasta que este el actor hijo se pare o cuando el mismo se haya reiniciado.
Para mostrar el comportamiento de las diferentes estrategias y cual es el ciclo de vida especifico de los actores (cuando se llama a los diferentes ‘hooks‘) he codificado en el proyecto los siguientes ejemplos.
Estrategia de supervisión por defecto
Test: ActorLetItCrashTestDefault.java
Comando maven mvn -Dtest=com.logicaalternativa.examples.akka.supervisorstrategy.ActorLetItCrashTestDefault test
Si se produce un excepción en un actor hijo, la estrategia por defecto en Akka es la de reiniciar el actor hijo, excepto si es un error irrecuperable:
- cuando se ha producido una excepción al inicializar el actor (ActorInitializationException)
- cuando ya se había parado el actor(ActorKilledException)
Esta estrategia cobra sentido cuando se quiere mantener un sistema estable. La idea subyacente es que cuando se produce un error el sistema debería volver a un estado consistente y esto se consigue reiniciando el estado del actor.
En este ejemplo, los pasos son:
- Se envía un primer mensaje ‘state‘ al actor ActorNoTypedLetItCrash. Este hará el reenvío del mensaje al actor hijo (ActorNoTypedDummyCheckLifeCycle) que devolverá la concatenación de los diferentes métodos por los que ha pasado hasta ese momento.
- Después se envía un mensaje con una excepción para que el actor hijo provoque la excepción.
- Por último se vuelve a enviar un mensaje ‘state‘ para ver por los eventos que se ejecutan cuando se reinicia el actor.
- Finalmente para poder ver todo el flujo, se para el actor.
El ejemplo permite comprobar el flujo completo del paso de los diferentes eventos a lo largo de la vida del actor hijo. En este caso con la estrategia de supervisión por defecto, es este:
Se llama al constructor
=> Llamada a aroundPreStart
=> Llamada a preStart
=> [[exception]] Se provoca una excepción
=> Llamada a aroundPreRestart
=> Llamada a preRestart
=> Llamada a postStop
=> Llamada al constructor (Se vuelve a crear el actor)
=> Llamada a aroundPostRestart
=> Llamada a postRestart
=> Llamada a preStart
=> Llamada a aroundPostStop
=> Llamada a postStop
Estrategia de supervisión: Escalar la excepción
Test: ActorLetItCrashTestEscalate.java
Commando maven mvn -Dtest=com.logicaalternativa.examples.akka.supervisorstrategy.ActorLetItCrashTestEscalate test
¿Qué ocurre cuando se elige una estrategia de supervisión de tipo ‘escalate‘? En este caso la excepción en el actor hijo provoca el error también en el actor supervisor. El comportamiento final depende entonces de la propia estrategia de supervisión de este último.
El ejemplo puede ayudar a verlo más claro. En este caso se configura el supervisor (ActorNoTypedLetItCrash) para que la estrategia de supervisión sea la de escalar la excepción. Cuando se provoca una excepción en el actor supervisado, el resultado es el mismo que si se hubiera producido en el supervisor.
El este caso el supervisor tiene la estrategia de supervisión por defecto, que lo reinicia, volviéndose a crear el actor hijo.
En el test se comprueba este hecho cuando se valida todo el ciclo de vida del actor hijo. Se arranca y después de la excepción, se para, para después volver a arrancar sin reinicio. Esto último provocado porque al reiniciarse actor supervisor, el hijo se para y se vuelve a crear:
Llamada a constructor
=> Llamada a aroundPreStart
=> Llamada a preStart
=> [[exception]] Se provoca una excepción
=> Llamada a aroundPostStop
=> Llamada a postStop
=> Llamada al constructor (Se vuelve a crear el actor)
=> Llamada a aroundPreStart
=> Llamada a preStart
=> Llamada a aroundPostStop
=> Llamada a postStop
Estrategia de supervisión ‘resume’: ‘Absorber’ la excepción.
Test: ActorLetItCrashTestResume.java
Comando maven mvn -Dtest=com.logicaalternativa.examples.akka.supervisorstrategy.ActorLetItCrashTestResume test
Si el supervisor adopta una estrategia de ‘resume‘ si se produce un error la excepción no produce ni el reinicio, ni la parada del actor supervisado. Aunque se haya producido el error, sigue levantado a la espera de procesar nuevos mensajes.
El test ayuda a comprender este tipo de supervisión. Se comprueba que cuando se produce una excepción al procesar un mensaje, no se hace ninguna llamada a los métodos del ciclo de vida, ni tampoco se escala la excepción. El siguiente mensaje lo procesa correctamente.
El ciclo de vida del actor supervisado con este tipo de supervisión será:
Llamada a constructor
=> Llamada a aroundPreStart
=> Llamada a preStart
=> [[exception]] Se provoca una excepción
=> Llamada a aroundPostStop
=> Llamada a postStop
Estrategia de supervisión ‘stop’: Parar el actor supervisado.
Test: ActorLetItCrashTestStop.java
Comando maven mvn -Dtest=com.logicaalternativa.examples.akka.supervisorstrategy.ActorLetItCrashTestStop test
En este caso, se para el actor supervisado cuando al procesar un mensaje ocurre una excepción.
En el ejemplo se fuerza esta situación. Si se provoca una excepción en el actor supervisado se comprueba que el actor no se vuelve a reiniciar. De hecho si se le vuelve a enviar un mensaje de estado, este se envía a la cola de ‘Dead Letters‘ porque la referencia al actor ya no apunta a un actor válido.
El ciclo de vida del actor es el siguiente:
Llamada a constructor
=> Llamada a aroundPreStart
=> Llamada a preStart
=> [[exception]] Se provoca una excepción
=> Llamada a aroundPostStop
=> Llamada a postStopLos mismos pasos que con la estrategia ‘resume‘. Pero en este caso no ha sido necesario parar el actor en el test porque ‘muere‘ después de provocarse la excepción.
Bus de eventos interno de Akka
Test: PublishSimpleSuscribeTest.java
Comando maven mvn -Dtest=com.logicaalternativa.examples.akka.bus.PublishSimpleSubcribeTest test
Akka poseé un bus interno que permite el envío de mensajes siguiendo el patrón publicador-suscriptor. Un ‘publicador‘ envía un mensaje sin saber quien van a ser los receptores. Los actores que quieran recibir ese tipo de mensajes deberán suscribirse a esa publicación.
![[Bus de eventos de Akka]](/wp-content/uploads/2015/10/busEvent-peque2.png) El paradigma cambia. En vez de enviar un mensaje a un actor concreto, es decir, “(Por favor) haz esto”, cuando se publica un mensaje en el bus se está diciendo “(A quien pueda interesar) ha ocurrido esto”
El paradigma cambia. En vez de enviar un mensaje a un actor concreto, es decir, “(Por favor) haz esto”, cuando se publica un mensaje en el bus se está diciendo “(A quien pueda interesar) ha ocurrido esto”
En este caso el ejemplo muestra un uso sencillo del bus de Akka para mostrar este patrón.
Se levantan dos actores suscriptores (del tipo ActorNoTypedLogEvent) que se suscribirán a mensajes de tipo Integer. La implementación de este actor es sencilla: registra los mensajes del tipo a los que está suscrito y si se le envía un mensaje ‘lastMessage‘ devolverá el último mensaje que ha registrado.
En el test después de levantar a los dos suscriptores se envía un mensaje al bus de Akka. Después se comprueba que el mensaje le ha llegado a ambos.
Dead letters
Test: DeadLettersTest.java
Comando maven mvn -Dtest=com.logicaalternativa.examples.akka.bus.DeadLettersTest test
Un ‘dead letter‘ se produce cuando no se ha podido entregar un mensaje a un actor. Un caso típico es cuando el actor receptor del mensaje ya no existe. El ‘dead letter‘ contiene el mensaje enviado, la referencia al actor que lo envía y la del que lo iba a recibir.
Por defecto Akka informa en el log de la aplicación los dead letters que se producen (esto es configurable). También pública esta información a través del bus de eventos de Akka, lo que permite que una aplicación tenga la posibilidad de una gestión específica de estos mensajes perdidos.
En el ejemplo para poder provocar un dead letter se crea un actor del tipo ActorNoTypedDummy pararlo para a continuación enviarle un mensaje. Este mensaje ‘se pierde‘ y es recogido como ‘dead letter‘.
Por otra parte en el ejemplo se está utilizando un actor del tipo ActorNoTypedLogEvent configurado para que suscriba en el bus de eventos de Akka los mensajes del tipo DeadLetter.
Cuando se manda un mensaje de ‘lastMessage‘ al actor ActorNoTypedLogEvent este devolverá la información del mensaje perdido en forma de DeadLetter.
Como comprobación final del test se validará la información contenida en el objeto DeadLetter: el mensaje y la referencia al actor receptor.
Hasta aquí este segundo artículo de Akka por ejemplos. El próximo y último artículo de esta serie será sobre actores tipados.
Espero que os sirva.
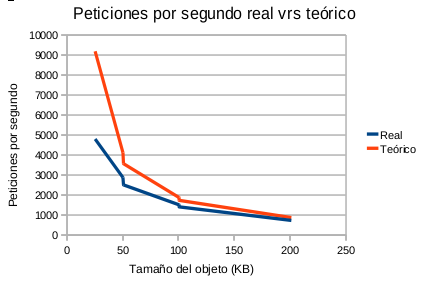
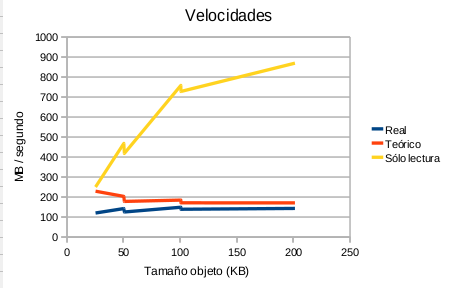
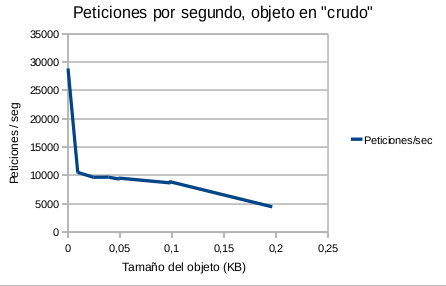
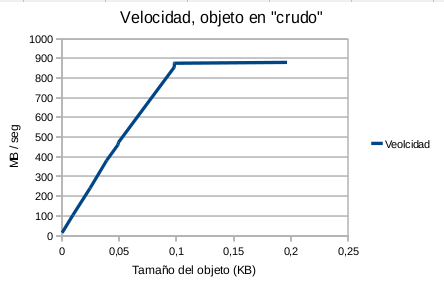
![[Robustez y rendimiento]](/wp-content/uploads/2015/01/robustezRendimiento.png) “Este artículo trata sobre la importancia de las pruebas de robustez y de rendimiento y su relación directa con la calidad del software, y lo importante que es medir y representar los datos en una gráfica.
“Este artículo trata sobre la importancia de las pruebas de robustez y de rendimiento y su relación directa con la calidad del software, y lo importante que es medir y representar los datos en una gráfica. ![[Cache]](/wp-content/uploads/2015/01/cache.png) La finalidad de la librería es tener un sistema de cache sencillo sin necesidad de instalación de extensiones como apc ni ni servicios como memcache. Tan sólo es necesario que el usuario del apache tenga permisos de escritura, cosa que es lo más común. Por esto es ideal para “alojamientos compartidos” de páginas web.
La finalidad de la librería es tener un sistema de cache sencillo sin necesidad de instalación de extensiones como apc ni ni servicios como memcache. Tan sólo es necesario que el usuario del apache tenga permisos de escritura, cosa que es lo más común. Por esto es ideal para “alojamientos compartidos” de páginas web.![[Concurrencia utlinzando modelo de actores]](/wp-content/uploads/2015/01/actores.png)