
(más => simular concurrencia, modelo de actores, de “pull request”,…)
“Este artículo trata sobre la importancia de las pruebas de robustez y de rendimiento y su relación directa con la calidad del software, y lo importante que es medir y representar los datos en una gráfica.
Un caso práctico, un sistema de cache PHP simpe basado en almacenamiento en ficheros. En teoría lento ¿verdad? ¿pero lo has comprobado?”
Introducción, Cache…
Cachear no es que sea nuevo, pero si está de rabiosa actualidad. El cacheo es una técnica fundamental dentro de los paradigmas de escalabilidad y rendimiento que se están implementando en la actualidad. Sus ventajas son claras a la hora de evitar tráfico en los cuellos de botella de una arquitectura, típicamente la base de datos. Las arquitecturas con cache compartida (con sistemas como Memcached o a otro nivel Redis) y colas de mensajes pasan a ser “la nueva forma” de hacer las cosas.
Está presente también en las tendencias actuales de arquitecturas basadas en microservicios. Algunas siguen la máxima “cache everything” (“Cachea todo lo que se mueva..” 🙂 )
Y a otro nivel, también hay un debate abierto con la movilidad y en el que ha entrado de lleno Linus Torvalds (1). Defiende que añadir más procesamiento en paralelo (más cores a los procesadores de los móviles) no es la solución y que las caches grandes son eficientes.
El cache también tiene sus problemas intrínsecos complejos. Por ejemplo, la invalidez de los valores cacheados. Si no se hace correctamente se puede trabajar con datos ‘antiguos’ y perder información. Problema antiguo… Martin Fowler (2), ha hecho famosa la cita de Phil Karlton
“There are only two hard things in Computer Science: cache invalidation and naming things.”
El caso práctico, cache simple en PHP
El objetivo de este post no es tan ambicioso como para meterse de lleno en este problema. En su tiempo para el post “Dar valor a los tweets: Interés, difusión, audiencia,… trasteando con el API de Twitter” necesitaba una librería para cachear los resultados del api de Twitter. Me decanté la librería php-cache de Emilio Cobos, me pareció sencilla, fácil de utilizar y configurar y suficiente para lo que necesitaba. Desde entonces llevo usándola también en otros proyectos.
El almacenamiento en memoria es lo más rápido para una cache. Esto, que en Java es sencillo de implementar, basta con almacenar el valor en un atributo estático de una clase para que este accesible en todos los hilos de ejecución, en PHP es necesario usar extensiones externas al core de PHP o utilizar memoria compartida. Esto último honestamente no creo que sea lo más se adecue dentro de este contexto en donde lo que busqué es la máxima sencillez.
![[Cache]](/wp-content/uploads/2015/01/cache.png) La finalidad de la librería es tener un sistema de cache sencillo sin necesidad de instalación de extensiones como apc ni ni servicios como memcache. Tan sólo es necesario que el usuario del apache tenga permisos de escritura, cosa que es lo más común. Por esto es ideal para “alojamientos compartidos” de páginas web.
La finalidad de la librería es tener un sistema de cache sencillo sin necesidad de instalación de extensiones como apc ni ni servicios como memcache. Tan sólo es necesario que el usuario del apache tenga permisos de escritura, cosa que es lo más común. Por esto es ideal para “alojamientos compartidos” de páginas web.
Su funcionamiento similar a otras librerías de este tipo. Está basada en la serialización de las variables, y su almacenaje en ficheros de texto. El código fuente es sencillo, ordenado y muy fácil de seguir.
Después de decirme a usarla y ver como funcionaba, me surgieron dos dudas. En su momento, en anteriores proyectos, tuve problemas de concurrencia en PHP cuando más de un proceso leía/escribía en el mismo fichero a la vez. Además que el acceso a cache tuviera acceso a disco «¿cuánto estaba penalizada la velocidad este motivo?»
Estas dos preguntas fueron la excusa para adentrarme en el mundo de las pruebas de rendimiento y de robustez. Otra pata importante dentro del desarrollo que aporta valor a la calidad del software. El resultado de todo esto está reflejado en lo que viene a continuación.
Adelanto que propuse unos cambios en el código y Emilio Cobos a tenido a bien aceptar mi ‘pull request‘, por lo tanto he pasado a ser un humilde, pero a la vez orgulloso contribuidor de php-cache.
Pruebas de robustez, concurrencia lectura/escritura de una clave de la cache
php-cache utiliza para cada clave de la cache un fichero donde almacena el valor «serializado«. Para probar la concurrencia cuando varios procesos leen/escriben en una misma clave de la cache diseñe dos test.
El primero de ellos, robustness-rw.test.php, lanza 10 procesos concurrentes, simulando 10 clientes ejecutando las mismas operaciones a la vez. Cada uno de ellos graba un valor en una clave de la cache y a continuación obtiene el valor de la misma clave de la cache. Estas dos operaciones las realiza cada proceso 50 veces (un total de 500 operaciones de escritura/lectura en total) cambiando cada vez el valor grabado de 3 posibles.
El valor obtenido de la cache tiene que ser igual a alguno de los tres valores posibles. Si es diferente o es nulo el valor se considera como invalido.
El segundo de los test de robustez, robustness-rw2.test.php es similar al anterior. En este caso además de guardar y obtener el valor se realiza una tercera operación de borrado de la clave de la cache. En este caso, el valor obtenido de la cache tiene que ser igual a alguno de los tres valores posibles o nulo. En cualquier otro caso se considera como inválido.
Los dos test están el directorio test repositorio principal de la librería ya que estaban incluidos en el ‘pull request‘ aceptado. En el README.md del directorio test está explicado más en profundidad lo que hacen y como se lanzan.
Simulando los clientes concurrentes, esquema basado en el modelo de actores
¿Cómo simular los clientes/peticiones concurrentes? Hay que tener en cuenta que el soporte multihilo no viene habilitado en una instalación tipo de PHP. El esquema que he seguido para simular la concurrencia he seguido en el paradigma de “modelo de actores”.
El script principal (actor principal) se encarga de lanzar los demás actores (procesos secundarios). En este caso son procesos PHP, en realidad una copia del mismo test que tiene un comportamiento diferente si “actúa” como actor secundario. Los secundarios se encargan cada uno de de hacer las 50 peticiones de escritura/lectura o escritura/lectura/borrado en una misma clave común.
Una vez lanzado los actores secundarios, el principal espera a que todos terminen para recoger los resultados y calcular la información estadística de los errores que se hayan podido producir.
Los mensajes entre el actor principal (el proceso) y el resto de actores (los procesos secundarios) los he montado utilizando también la librería php-cache.
Este es el flujo seguido:
![[Concurrencia utlinzando modelo de actores]](/wp-content/uploads/2015/01/actores.png)
- El proceso principal crea los actores pesándoles como parámetro una clave auxiliar de la cache (diferente para cada proceso) en la que escribirán el resultado. Los actores secundarios una vez hayan terminado su trabajo escriben en esa clave de la cache sus resultados.
- El proceso/actor principal se encarga de preguntar el estado de los actores lanzados, comprobando si existe la clave auxiliar en la cache que ha asignado a cada proceso.
- Una vez haya leído todas las claves auxiliares (todos los procesos hijos han terminado) calcula las estadísticas y muestra los resultados.
Los mensajes son inmutables, los actores secundarios sólo escriben en la clave asignada y el principal sólo lee las claves que ha asignado.
Resultado de los test de robustez y modificación del código
Al lanzar los test de robustez comprobé que en estos casos extremos de concurrencia la librería podía devolver la lectura de datos corruptos.
Hice una pequeña modificación en el código. Ahora siempre que se almacena un valor de una clave se escribe en un archivo temporal. Si la escritura es correcta, el fichero temporal se renombrará al definitivo utilizando la función rename de PHP. Esta función, es atómica si se realiza en el mismo sistema de ficheros. Este es el caso ya que se trabaja en el mismo directorio.
Volviendo a lanzar los test con este cambio ya no se obtienen datos corruptos y tanto la lectura se ejecutan sin errores.
Después de hacer un ‘fork‘ del repositorio y propuse los cambios lanzado un ‘pull request‘. Esta petición ha sido aceptada y los esta modificación está ya en el repositorio oficial de php-cache en GitHub
Pruebas de rendimiento. Mini benchmark
php-cache es una librería basada en lectura/escritura de ficheros, así que su velocidad depende de lo rápido que sea el acceso a disco y su velocidad de lectura.
En el repositorio de GitHub he subido un pequeño script (benchmark.test.php) que permite realizar medidas del acceso a un valor de la cache y cual sería el tiempo medio por respuesta.
Además como referencia se calcula el valor medio que se tarda en recuperar el objeto de su representación en cadena cuando sus datos están en memoria sin acceder a disco. Es decir, el valor teórico ideal que se alcanzaría si el coste de tiempo de acceso a disco fuera cero.
La información que devuelve el test es tanto el coste real como el teórico, número de peticiones realizadas, tiempo total y las estadísticas con datos sobre la media de milisegundos que ha tardado en hacer una petición y el cálculo de las peticiones por segundo.
… Dibujando y sacando conclusiones
Las conclusiones se pueden pueden ver de las siguientes gráficas:
-
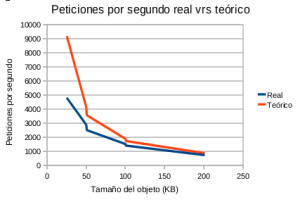
- Gráfica 1: Peticiones/segComparando los valores real y teoríco
-
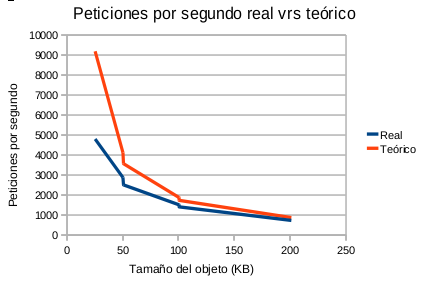
- Gráfica 2: Velocidades comparadas tamaño del objeto cacheado
En la primera (Gráfica 1) se muestra la información de los datos de las peticiones por segundo de los dos procesos, el real y el teórico. Si se observa con atención, para objetos de poco peso el valor del número de peticiones es muy dispar entre las dos gráficas. Sin embargo, según va aumentando el peso del objeto guardado en cache, los dos valores se acercan hasta que casi el valor real es igual al ideal … Pero « ¿por qué puede pasar esto?»
Para poder poner un poco de luz en el asunto he creado la Gráfica 2. Se muestra la velocidad en MB por segundo en obtener el objeto. Una de las líneas es la velocidad de las peticiones reales, otra es como sería el calculo ideal y la línea amarilla es la velocidad que tarda en leer de fichero, es decir el tamaño del objeto dividido por la diferencia de los dos tiempos (real menos teórico).
Se puede observar, que mientras las velocidades de los procesos teórico y real tienden a ser constantes, la velocidad de lectura crece. En proporción, cuanto más grande es el objeto menos tarda en leerlo.
Con los objetos más grandes, al ser el proceso de lectura mucho más rápido que el proceso de «des-serialización«, el peso del primero pasa a ser despreciable en comparación con el segundo. Es la velocidad del proceso más lento (la «des-serialización«) la que marca la velocidad al obtener un valor de la cache.
La librería php-cache también tiene la posibilidad de guardar los datos en «crudo» sin serializar para almacenar cadenas, por ejemplo, para cachear la salida html directamente. Las siguientes gráficas (Gráficas 3 y 4) son los datos obteniendo un valor de la cache en «crudo«. Muestran mejor a la conclusión que quiero llegar.
-
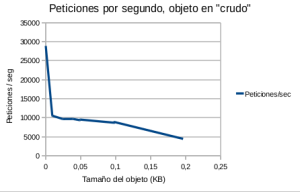
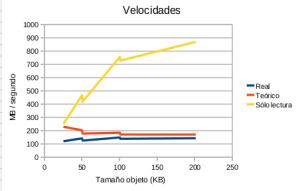
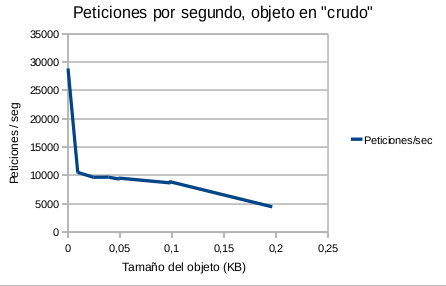
- Figura 3: Peticiones por segundo, objeto en crudo
-
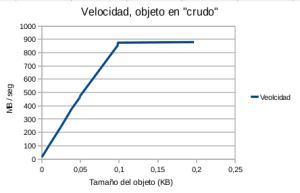
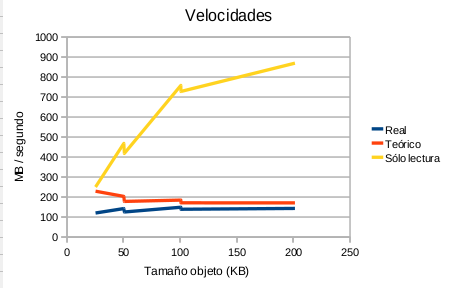
- Figura 4: Velocidad, objeto en crudo
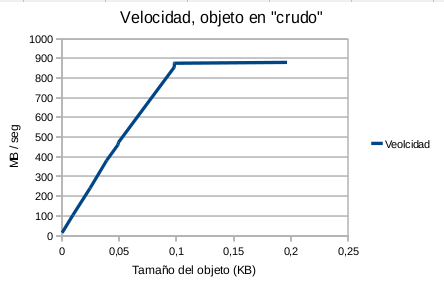
En este caso la velocidad de lectura aumenta según lo hace el tamaño del objeto a leer y tiende a un máximo.
Y vuelvo a repetir «¿Por qué pasa esto?» Sorprendente, …o no tanto. La respuesta es que el sistema operativo viene al rescate y entra en acción el buffer cache del disco (3).
El acceso a disco es mucho más lento que el acceso a memoria. El buffer cache del disco del sistema operativo sirve de colchón amortiguador de esta diferencia de velocidades de acceso. Mantiene en memoria (cache, …su cache) aquellos datos que leen la misma parte del disco varias veces durante periodos relativamente cortos de tiempo. Con respecto a este punto también he hecho pruebas realizando un sleep de dos segundos entre peticiones y la velocidad era la misma por lo que el los datos se conservaban en el buffer.
Recordar que este buffer no realiza cache de archivos, pero sí de bloques. Cuantos más bloques del fichero están en cache más rápido será la lectura y también añadir que el buffer de lectura de disco es transparente y lo gestiona el sistema operativo.
Resumiendo, cuanto mayor sea el tamaño del objeto a cachear y mayor sea el número de lecturas, php-cache pasa de ser un sistema cache basado en disco, «a priori» lento, para convertirse de «facto» en un sistema de cache basado en memoria y pasar a ser rápido. Y recordemos que estas circunstancias, objetos grandes y costosos de calcular con cierta carga de lectura, son precisamente una de las razones por las que se valora adoptar un sistema de cache.
Conclusiones
Siempre que se evite la optimización prematura evitando complicar innecesariamente el software (optimizar es un vicio, cuando se empieza no se sabe como parar), las pruebas de robustez y de rendimiento pueden ser unas herramientas muy útiles.
Permiten valorar como se comportará el producto que estás desarrollando o como lo hará el que estás pensando en adoptar… Sabemos que en muy pocas ocasiones los errores que surgen en un entorno de producción son reproducibles, pero que duda cabe que estas pruebas dan un plus de confianza en el software desarrollado. Y puede, como en este caso concreto, que te lleves una sorpresa para bien y se comporte mucho mejor de lo que en un principio podías esperar.
Otra conclusión, siempre que se mide se debe dibujar. Es importante reflejar los datos en un gráfico. Esto ayuda a vislumbrar una tendencia en los datos y obtener respuestas.
Y por último romper una lanza en favor de PHP. En algún sitio he leído que si «PHP fuera un arma se podía comparar con la manguera que pones al escape del coche para intentar suicidarte«…
No pienso así, PHP es un lenguaje al que tengo especial cariño y su simplicidad y potencia está demostrada con esta clase php-cache. Con unas pocas líneas tienes un sistema de cache muy competente y fiable que puedes usar sin problemas en proyectos sencillos y en el que puedes almacenar un montón de valores en la cache… tantos como espacio tengas en el disco duro.
Espero que os sirva.
Referencias
- [Linus: The whole «parallel computing is the future» is a bunch of crock] (highscalability.com)
- [TwoHardThings] (martinfowler.com)
- [El Buffer Cache] (tldp.org)